本章内容
1、字符串索引
2、字符
3、字符串切片
4、表尊字符串函数
5、正则表达式
-----------------------------------
在Python中,字符串是除了数字外最重要的数据类型;它是一种聚合数据结构,这让我们有基础初探索引和切片--用于从字符串中提取子串的方法;本章节还有另外一个非常重要的内容--正则表达式;
1、字符串索引
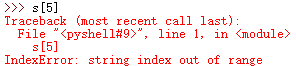
在处理字符串的时候,我们需要处理字符串中的单个字符,例如 s = 'apple' 我需要访问 e 这个字符,则需要使用字符串索引来完成;例如下面的代码:

其中"[]"中的数字就是索引信息;这里需要注意的是,索引信息是从 0 开始,到 n-1 结束;如果从后算起,则为负数索引:

负数索引信息,从 -1 到 -n 来记录字符串信息;
如果超出访问,则会导致报错;
同时,我们也可以通过for循环来访问字符串,并返回字符编码的总合;代码如下:
# codesum.pydef codesum1(s) """ Returns the sums of the character codes of s. """ total = 0 for c in s: total = total + ord(c) return total
2、字符
Python下的字符使用的是Unicode编码,字符转编码使用 ord() 函数,而编码转字符使用 chr() 函数:

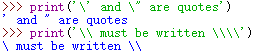
转义字符:例如换行字符、回车字符、制表符都是不可见的。 \ 用来对字符进行转义,实现字符本身的意思;
\ 转义符
\n 换行符
\t 制表符
\r 回车
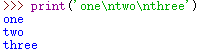
表示换行的标准方式使用字符 \n:
3、字符串切片
字符串指定两段索引信息,就可以对字串进行切片,如下:
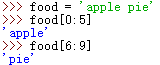
如果切片从0开始,可以不用写,结束不用些,如果打印全部字符串 : 也可以这样来切片:
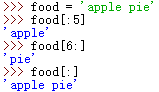
切片示例如下(提取文件后缀):
# extension.pydef get_ext(fname): """ Returns the extension of file fname. """ dot = fname.rfind('.') if dot == -1: #fname中没有 return '' else: return fname[dot + 1:] 
有时候,我们也需要使用负数索引信息来进行切片;

4、标准字符串函数
我们可以通过一些有关字符串的函数,来指定字符串的功能;
a\字符串测试函数:
s.endwith(t) s以字符串t结尾
s.startswith(t) s以字符串t打头
s.isalnum() s质保换字母或数值
s.isalpha() s只包含字母
s.isdecimal() s只包含表示十进制数字的字符
s.isdigit() s只包含数字字符
s.isidentifier() s是非法的标识符
s.islower() s只包含小写字母
s.isnumeric() s只包含数字
s.isprintable() s只包含可打印的字符
s.isspace() s只包含空白字符
s.istitle() s是一个大小写符合标题要求(title-case)的字符串
s.isupper() s只包含大写字母
t in s s包含字符串t
这些函数都是用来进行字符串测试,他们的返回值都是布尔类型(False或者True),所以它们也叫作布尔函数或者谓词;
b\搜索函数
在字符串中查找符合条件的字串;比如index或者find,它们之间的差别在于没有找到特定字串的时候的情形,如下图:
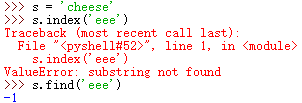
index是报错,而find的返回值是 -1;
注意:字串搜索默认是从左至右搜索,但是如果是 r 打头的函数就回从右自左搜索;

搜索函数:
s.find(t) 如果没有找到字串t,则返回值 -1;否则返回值t在s中其实位置;
s.rfind(t) 与find相同,但从右往左搜索;
s.index(t) 与find相同,但如果s中找不到t,则引发ValueError异常
s.rindex(t) 与index相同,但从右往左搜索
c\改变大小写的函数
Python提供了各种修改字母大小写的函数,如下:
s.capitalize() 将s[0]改为大写,其余小写
s.lower() 让s的所有字母都小写
s.upper() 让s的所有字母都大写
s.swapcase() 将小写字母改为大写,并将大写字母改为小写
s.title() 让s的大小写符合标题的要求
设置字符串格式的函数如下:
s.center(n,ch) 包含n个字符的字符串,其中s位于中央,凉拌用字符ch来填充
s.ljust(n,ch) 包含n个字符的字符串,其中s位于左边,右边用字符ch填充
s.rjust(n,ch) 包含n个字符的字符串,其中s位于右边,左边用字符ch填充
*s.format(vars) 它是用于设置字符串格式的微型语言;
使用format如下:
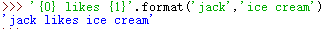
‘jack’作为第一部分,‘ice cream’为第二部分,索引信息分别为 1 ,2 ;这时候就回填写在前面;
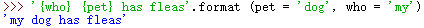
不使用 0 , 1的索引信息,直接赋值也可以;
d\剥除函数
它用于删除字符串开头或者结尾的多余的字符;
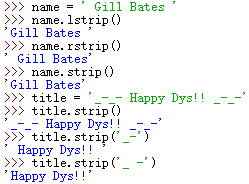
s.strip(ch) 从s开头和末尾删除所有包含在字符串ch中的字符;
s.lstrip(ch) 从s开头(左端)删除所有包含在字符串ch中的字符;
s.rstrip(sh) 从s末尾(右端)删除所有包含字符串ch中的字符;
f\拆分函数
拆分函数将字符拆分为多个字符串,常见函数如下:
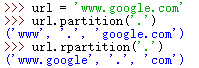
s.partition(t) 将s拆分为三个字符串(head,t和tail),其中head为t前面的子串,而tail为t后面的子串;
s.rpartition(t) 与partition相同,但从s的右端开始搜索t;
s.split(t) 以t为分隔符,将s划分成一个系列子串,并返回一个由这些子串组成的列表;
s.rsplit(t) 与split相同,但从s的右端开始搜索t
s.splitlines() 返回一个由s中的各行组成的列表
这两个函数总是返回一个这样的值:它由三个字符串组成,形式为(head,sep,tail)。这种返回值为元组(后面介绍);
g\替换函数
s.replace(old,new) 将s中的每个old替换为new
s.expandtabs(n) 将s中的每个制表符扩展为空格,制表符宽度为n

h\其他函数
s.count(t) t在s中出现的次数
s.enode() 设置s的编码
s.join(seq) 使用s将seq中的字符串连接成一个字符串
s.maketrans(old.new) 创建一个转换表,用于将old中的字符改为new中相应的字符;请注意,s可以是任何字符串,它并不影响返回的转换表;
s.translate(table) 使用指定转换表(使用maketrans创建的)对s中的字符进行替换
s.zfill(width) 在s左边添加足够多的0,让字符串长度为width
函数translate和maketrans很实用。例如,下面是一种将字符串转换为“脑残体”(leet-speak)的方式:

函数zfill用于设置数值字符串的格式:

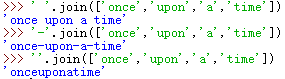
函数join就可以将很多字符串拼接起来:
5、正则表达式
正则表达式是用来简易的描述一个字符串的方式,可以高效的匹配字符常见的字符串;
简单的正则表达式:例如 cat? 就可以表示 cat 和 cats
另一个符号位 | 表示或者:例如 a|b|c 意思为 a 或者 b 或者 c
* 则表示无穷个字符串:a* 表示 ‘ ’ ‘a' 'aa' 'aaa' ... 【a+ 和 a* 想同,但是不包含 ' ' 空格符;】
如果要复制字符串,则要使用 () 就行:例如,(ha)* 表示 'hahaha'
实例:
# allover.pydef is_done1(s): return s == 'done' or s == 'quit'
改用正则表达式,改写如下:
# allover.pyimport re #使用正则表达式,导入re库;def is_done2(s): return re.match('done|quit',s)!= None #使用函数re.match(regex.s) re.match(regex.s) regex与s不匹配的时候返回None,否则返回一个特殊的正则表达式匹配对象。因此,可以只检查返回值是否为None;
随着程序的增大,使用正则表达式更加方便;
再举一个例子,识别逗人的字符串:
# funny.pyimport redef is_funy(s): retrun re.match('(ha)+!+,s)!= None 其中 (ha)+!+ 可以表示 haha!!! ha和!都可以是任意长度;【不能是空】
re库其实非常庞大,其中大量的正则表达式函数可以用于执行字符串处理任务,如匹配、拆分、和替换等;还有提高常用字符的捷径。
模块re的文档:http://docs.python.org/3/library/re.html